
Šachy a procesory
Chess and CPUs
1. 2014
|
Šachy a procesory
|
Klasický šach na jednom jádře - vztah GHz, ELO,
hloubka propočtu /Classic one core Chess - GHz, ELO, plies
Víceprocesorové a vícejádrové stroje
/Multiprocessor and multithread machines
64bitové motory /64bit Chess
Hash tabulky /Hash tables
Šachové benchmarky /Chess Benchmarks
Rychlé šachové počítače /Quick Chess Computers
Pro úvodní úvahy uvažujme PC s jedním jádrem, případně programem, který
využije jen jedno
jádro.
V určitém rozsahu lze považovat za přibližně lineární. Prohloubení propočtu
jeden polotah vede k růstu ELA o 100-150 bodů.
Tento fakt nelze pravděpodobně teoreticky zdůvodnit a má spíš experimentální povahu.
Níže uvedené měření je z roku 2007.
Gerhard Sonnabend (Loop-Support)
Loop vs Loop
Tiefe Tiefe Ergebnis Elo-Diff. Zeitverbrauch
...................................................................
6 vs 5 107.0 - 33.0 (+90 =34 -16) +204 n/a
7 vs 6 106.5 - 33.5 (+85 =43 -12) +201 n/a
8 vs 7 99.5 - 40.5 (+75 =49 -16) +156 2.292
9 vs 8 101.0 - 39.0 (+77 =48 -15) +165 2.300
10 vs 9 96.5 - 43.5 (+61 =71 -08) +138 2.288
11 vs 10 97.5 - 42.5 (+69 =57 -14) +144 2.310
12 vs 11 90.0 - 50.0 (+54 =72 -14) +102 2.256
-------------------------------------------------------------------
Rybka vs Rybka
Tiefe Tiefe Ergebnis Elo-Diff. Zeitverbrauch
...................................................................
6 vs 5 107.0 - 33.0 (+84 =46 -10) +204 1.740
7 vs 6 99.0 - 41.0 (+72 =54 -14) +153 1.900
8 vs 7 100.5 - 39.5 (+71 =59 -10) +162 1.853
9 vs 8 91.5 - 48.5 (+59 =65 -16) +110 1.770
-------------------------------------------------------------------
Rychlost jednojádrového stroje je v dobrém přiblížení lineárně úměrná pracovní
frekvenci, která se nyní udává v GHz (GigaHertzech).
Jenže šachová hra je exponenciální - vidět o polotah dál je čím dál pracnější.
Závislost ELA na rychlosti je proto zhruba logaritmická
- to je inverzní funkce k exponenciále.
V klasických dobách rozvoje šachového programování platilo "zlaté
pravidlo 100", podle kterého zdvojnásobení rychlosti stroje zvedlo
ELO o 100 bodů.
Dnes se ta stovka značně snížila někam na 50-70.
ELO2 = ELO1 + K * log2 (MHz2/MHz1) K = 50-70
A classical "gold" rule (doubled MHz = +100 ELO) should be today changed to around a half.
Měření z roku 2002 - SSDF listina
| program | AMD TBird 1200 MHz |
AMD K6/2 450 MHz |
Difference |
| DeepFritz | 2726 | 2654 | 72 |
| Gambit Tiger | 2720 | 2640 | 80 |
| ChessTiger | 2703 | 2632 | 71 |
| Shredder | 2699 | 2600 | 99 |
| Gandalf | 2653 | 2532 | 121 |
| průměrně/average | 88.6 |
ELO2 = ELO1 + K * log2 (MHz2/MHz1) => K = 88.6 / log2 (1200/450) = 63.24.09.03
Toto číslo lze částečně odvodit i teoretickými úvahami. Je-li v průměrné
pozici dejme tomu 25 možných tahů, pak by při brutální metodě programování
musel počítač ke zvýšení hloubky zrychlit 25x. Ale tzv. alfa-beta
odsekávání sníží podle matematické teorie při dobrém úvodním třídění počet uzlů
až na odmocninu. Odtud tedy plyne 1 polotah = 5x rychlost = (100-150) ELO. A kyž
bude rychlost jen 2x, dostáváme se k výše uvedeným číslům.
Další zvyšování frekvence procesorů vázne na
fyzikálních limitech, proto výrobci jsou cestou zabudování více jader do jednoho
čipu.
Zatímco u vhodně naprogramovaných matematických výpočtů může rychlost narůst
lineárně s počtem jader, tak rozdělení šachové analýzy mezi více "analytiků" je obtížný problém s nízkou
efektivitou.
K využití potřebujete vícejádrový motor, poznáte ho obvykle podle jména
Deep nebo MP.
Bývá
obvykle dvakrát dražší, ale efektivita není příliš
vysoká.
Zdroj CEGT Blitz 40/4 2GHz http://www.husvankempen.de/nunn/blitz.htm
|
|
1CPU |
2CPU |
4CPU |
Dif1-2 |
Dif2-4 |
Dif1-4 |
|
Rybka 3.0x64 |
3112 |
3154 |
3196 |
42 |
42 |
84 |
|
Naum 4.0 x64 |
n/a |
3057 |
3095 |
n/a |
38 |
n/a |
|
Deep Frifz 11 |
2938 |
2975 |
3024 |
37 |
49 |
86 |
|
Slockfish 1.4 x64 |
2902 |
2936 |
3006 |
34 |
70 |
104 |
|
Zappa MX II x64 |
2911 |
2958 |
3023 |
47 |
65 |
112 |
|
Hiarcs 12.1 |
2841 |
2913 |
2972 |
72 |
59 |
131 |
|
Shredder WM Bonn |
2912 |
2948 |
3011 |
36 |
63 |
99 |
|
Deep Sjeng 3.0 x64 |
2861 |
2911 |
2959 |
50 |
48 |
98 |
|
Bright 0.4a |
2819 |
2877 |
2926 |
58 |
49 |
107 |
|
Loop M1 |
2817 |
2857 |
2886 |
40 |
29 |
69 |
|
average |
2901 |
2959 |
3010 |
46 |
51 |
99 |
Třeba u Rybky dostanete zdvojením procesoru přínos kolem 40 ELO bodů, zatímco zdvojnásobením rychlosti, jak jsme ukázali nahoře, můžete dostat 50-70 ELO.
Chcete-li pochopit, proč je tomu tak, vzpomeňte si na staré časy, kdy při
zápasech družstev se pečetilo a dohrávalo za hodinu.
Analyzovalo celé družstvo a mnohdy to dopadlo hůř, než kdyby se hráč někam
zavřel a analyzoval v klidu sám.
Podobný chaos musí zvládat i programátor deep motoru, který řeší obtížný
problém, jak analýzu racionálně rozdělit mezi větší počet hráčů.
Jeden z nejpokročilejších algoritmů má podle výše uvedeného měření
Hiarcs.
Skvělá pověst se šířila kolem Rybka clusteru, který
využívá v síti spojené počítače s řádově stovkou jader.
Vzhledem k vysoké ceně pronájmu neexistují ale údaje o efektivitě tohoto custeru
a nejnovější pokusy ukázaly, že Houdini 3.0 na 16jádovém stroji Rybku cluster 64
porazí.
Dalším zajímavým jevem u vícejádrového šachu je špatná reprodukovatelnost měření, kterou ilustruji na měření z roku 2008.
Použil jsem dva plnohodnotné thready s Core2Duo
6320, 1G RAM.
Jako motor jsem vzal Hiarcs 12 UCI MP, který má pověst
velmi účinného "využívače" více jader.
Testoval jsem pod Win XP Pro, Fritz 11 GUI, 128M hash.
Mezi testy samozřejmě vymazány hash tabulky a také samoučící soubor
hiarcs12mp.lrn.
K testování jsem vybral dvě pozice, kde motor potřebuje k nalezení řešení desítky vteřin. Méně by vneslo systematickou chybu, delší časy nic moc nepřinášejí a zbytečně prodlužují testování.
|
5rk1/1r1qbnnp/R2p2p1/1p1Pp3/1Pp1P1N1/2P1B1NP/5QP1/5R1K w - - 0 1 1. Dxf7, vyřešeno je-li indikováno s hodnocením >3.00 |
r1bn1rk1/pp3p1p/6p1/2bR2N1/2B2B2/q1P1P3/2Q2PPP/4K2R w K - 0 1 1.Jxh7, vyřešeno při indikaci s hodnocením >2.00 |
||||
| 2 thready cca 600kN/s | 1 thread cca 300 kN/s | 2 thready cca 600kN/s | 1 thread cca 300 kN/s | ||
| sec | sec | sec | sec | ||
| 15 | 21 | 26 | 16 | ||
| 14 | 21 | 16 | 16 | ||
| 12 | 21 | 11 | 16 | ||
| 12 | 21 | 37 | 16 | ||
| 12 | 21 | 16 | 16 | ||
| 14 | 21 | 15 | 16 | ||
| 15 | 21 | 11 | 16 | ||
| 11 | 21 | 13 | 16 | ||
| 15 | 21 | 28 | 16 | ||
| 27 | 21 | 12 | 16 | ||
|
průměr 10 měření 14,7 sec |
průměr 10 měření 21 sec | průměr 10 měření 18,5 sec | průměr 10 měření 16 sec! | ||
Závěry
1. Jednoprocesorový Hiarcs analyzuje "čistě", výsledky jsou téměř stoprocentně reprodukovatelné v každém průchodu.
2. U DeepHiarcs naopak výsledky u stejné pozice kolísají. Od skvělých časů s téměř teoreticky maximálním urychlením (11/21 sekund) až po výsledek horší než u single verze.
3. Velmi kolísá i statistický výsledek od pozice k pozici.
Charakter obou pozic vypadá dost podobný, ale výsledek se přesto diametrálně
liší.
Zatímco v první pozici snadno opakovaně prokážete růst výkonnosti až o 40 procent,
ve druhé pozici použití dvou jader očividně spíš škodí.
Měření efektivity proto není možné provést za pár hodin otestováním
desítek pozic.
Skutečná hodnota by musela být určena měřením stovek až tisíců pozic a ještě
lépe sehráním velkého množství partií.
Další pokusy různých autorů kolísání výsledků u deep motorů
potvrdily.
Věc se vysvětluje tak, že při žádném měření nemůžete mít Windows ve stejném
stavu. I když vypnete všechny antiviry, messengery a podobné záležitosti, stále
na pozadí
běží desítky služeb, pro které si systém potřebuje náhodně vypůjčit jedno
jádro.A i kdyby to bylo jen jedenkrát na krátký čas, může to úplně změnit průběh
šachového výpočtu.
Vraťme se k naší analogii - společné analýze družstva při přerušení. V prvním
pokusu jeden hráč v kritické pozici šťastnou rukou zahraje správný kritický tah,
čímž družstvo
nasměruje vhodným směrem a pak už to jde samo. V druhém pokusu si ten hráč musí
odskočit a i když se za dvě minuty vrátí, na šachovnici už mezitím stojí jiná
pozice a všechno je úplně jinak.
Zatímco pokud bude hráč analyzovat sám, tak po návratu může pokračovat kde
přestal a výsledek to prakticky neovlivní.
HT - uvedený Intelem v roce 2002 - byla první možnost, jak se za rozumné ceny dostat k dvoujádrovému šachu. V jednom procesoru byly jakoby dva, ale proti dnešním plnohodnotným Dual a Quad Core procesorům byly ty HT neplnohodnotné. Nešlo totiž u úplné procesory, ale některé části měly společné. Proto na sebe musely často čekat a při nasazení HT rychlost jednoho jádra klesala.
Ani dnes není HT zcela mrtev a používá se jako doplněk vícejádrových procesorů. Intel Core i7-3770K má 4 poctivá (plnohodnotná) jádra a každé z nich má ještě HT. Takže správce zařízení ve Windows indikuje 8 jader.
Dnes už je zřejmé to, kolem čeho se léta chodilo jako kolem horké kaše. HyperThreading se na šachy nehodí a jeho nasazením výkon spíš klesne. Citujme z manuálu špičkového programu Houdini Roberta Houdarta.
The architecture of Houdini (and of chess engines in general) is not very
well suited for hyper-threading; using more threads than physical cores will
usually degrade the performance of the engine. Although the hyper-threads often
produce a slightly higher node speed, the increased inefficiency of the parallel
alpha-beta search more than offsets the speed gain obtained with the additional
hyper-threads. To give a practical example, it's more efficient to use 4 threads
running at 2,000 kN/s each than 8 threads running at 1,100 kN/s each, although
the latter situation produces a higher total node speed. For this reason it's
best to set the number of threads not higher than the number of physical cores
of your hardware.
Architektura Houdini (ale ani žádného jiného šachového motoru) není vhodná
pro nasazení HT. 4 jádra běžící rychlostí 2kN/s dávají sice matematicky nižší
součin, než 8 jader běžících rychlostí 1.1 kN/s,
ale vzhledem k nízké efektivitě využití paralelismu v šachu je první varianta
výrazně efektivnější.
Závěr je jasný, HT na šachy nepoužívat. Třeba pro zmíněnou i7 využívat 4 jádra.
Jak už bylo řečeno výše, zrychlovat procesory růstem frekvence narazilo na
fyzikální meze a hledají se proto jiné cesty.
Vedle vícejádrových procesorů se také rozšířily verze s možností 64bitového
instrukčního souboru.
Zatímco v klasických Pentiích se zpracovávalo najednou 32 bitů informace, teď je
to 64 bitů. U vhodně napsaného programu to může výpočty urychlit až dvojnásobně.
Je nutný novější procesor s 64 bitovým rozšířením.
AMD má rozšíření jménem AMD64, které drží prvenství
U Intelu se jmenuje EMT64 a od jara 2006 ho mají většinou i levné Celerony. V
poslední době se mluví o Intel64.
Jsou prakticky kompatibilní.
Pro spouštění 64 bitových aplikací je nutný 64 bitový operační systém.
| 32 bitový systém (Windows XP Pro, Vista, Window7, Windows 8) |
64 bitový systém (Windows XP Pro, Vista, Window7, Windows 8) |
| jen 32 bitové aplikace | 32 bitové aplikace i 64 bitové aplikace |
Pod 64 bitovým OS tedy spustíme vše.
Dnes už se proto nové Windows 7a Windows 8 instalují jako 64bitové. 32bitová verze je spíš exotika a nasazuje se výjimečně z důvodů spouštění starých DOSových programů, obvykle účetnictví, lékařského softwaru apod.
Pro úplnost, Windows XP Pro 64 byl tak trochu experimentální bastl a není kompatibilní s novými verzemi Fritze a ChessBase.
Výrazné zrychlení šachového motoru není automaticky garantováno!
Někteří programátoři se domnívali, že když mají motor třeba v C++, tak stačí zakoupit nový překladač, zvolit parametr /64 a je vyřešeno.Bohužel není.
Marc Uniacke dal bezelstně v 10/2006 k testování svého Hiarcse X54 UCI/64bit,
ale od té doby další 64bitová verze nebyla. Naměřili mu totiž zrychlení 2.5
procenta.
Tutéž chybu udělala ChessBase s lehce předraženým DeepFritzem 10. Vedle
multiprocesorů byl ohlášen i běh na 64bitech. Ale problém asi zjistili sami,
dokonce natolik včas, že mohli začít mlžit a nakonec přesvědčili zákazníky, že ani žádnou
64bitovou verzi neslibovali. Vysoká cena ovšem zůstala a 64bitovou verzi nemá
ani DeepFritz 13.
Záleží na vnitřní stavbě programu. Pokud je reprezentace šachovnice klasická
matice 8x8 (nebo 10x8) v bajtech (jako z učebnice programování), pak je věc skoro ztracená.
Tahy se totiž
provádějí většinou přičítáním/odčítáním, kde 64bitová aritmetika nemá skoro
žádný význam.
Chytřejší autoři modernějších programů použili tzv. bitboardovou
reprezentaci, kdy šachovnice je modelována řadou 64 bitových masek. Například
jedna pro bílé pěšce, druhá pro černé atd.
Tahy a testy se provádějí logickými operacemi nad těmito maskami. Ty se ale na
64bitovém stroji provádějí najednou, takže důležité opakované sekvence
generování tahů běží dvakrát rychleji.
Skvělá je především Rybka a Zap!Chess, běžící o 30-40 procent
rychleji. A samozřejmě celá nová generace jako Critter
nebo Houdini.
Zato klasické programy buď 64bitovou verzi buď vůbec nemají (Fritz, Hiarcs) nebo je její zrychlení bezvýznamné (Shredder) .
V tomto bodě panuje nejvíc pověr a mýtů. Ve skutečnosti se věc liší podle
typu motoru.
UCI motor je samostatná nezávislá konzolová EXE aplikace, komunikující s
GUI textovými příkazy přes rouru standardního vstupu a výstupu. Koneckonců
můžete si ho spustit a ovládat z příkazové řádky, což je nejjednodušší šachové
GUI. ChessBase nativní motor ENG je přejmenovaná dynamicky linkovaná knihovna
DLL, tedy v principu součást GUI.
U 32bitových aplikací měly CB nativní navrch právě díky užšímu výkonově
vyladěnému propojení.
V době náběhu 64bitů se ovšem karta obrací.
Kdo četl pozorně, už mu asi svítá.
64 bitový UCI motor lze bez problémů spustit z 32 bitového GUI,
např. Arény, Fritze, CB11.
64 bitový CB nativní motor vyžaduje naopak i 64 bitové GUI.
Po pravdě řečeno, 64 bitový CB nativní existuje jen jeden - Zap!Chess z dubna
2006.
Na DVD se k němu dodávala experimentální 64bitová verze Fritz GUI takové
kvality, že na 3 počítačích ze 4 nešla vůbec spustit.
Service Pack to sice spravil, ale od té doby na to v Hamburku kašlou.
V roce 2012 se objevila 64bitová verze ChessBase12.
Její hlavní pointou však není spouštění motorů, ale alokace více
paměti pro rychlé hledání v databázích.
Hash tabulky jsou jedním z nejdůležitějších objevů šachového programování.
První klasické speciály měly velkou pevnou paměť programu („ROMku“), a jen
malou přepisovatelnou paměť (RAM), která byla tehdy velmi drahá. Ukládala se
v ní jen pozice a pár důležitých proměnných. „Co jiného?“, říkali jsme
tenkrát.
Jenomže v šachové praxi se vyskytují případy, kde aparát s malou RAM selhával.
Jde o pozice s možností přehazování tahů, jako třeba pěšcové koncovky. A takový
klasický program se pak doslova zahltil výpočty typu 1.Kf2 Ke7 2.Ke3 Ke6, 1.Ke2
Kf7 2.Ke3 Ke6, 1.Kf2 Kf7 2.Ke3 Ke6, 1.Ke2 Ke7 2.Ke3 Ke6 aniž mu došlo, že
na konci analyzuje a hodnotí do „zblbnutí“ stále tu samou pozici.
Je jen jedna cesta, jak tomu zabránit. Všechny již probrané pozice se musí
ukládat ve velké paměti RAM a když vznikne pozice nová, nejdřív se
podívat, jestli „už náhodou nebyla“. A musí se to dělat proklatě
rychle, aby to moc nezdržovalo. Odpovědí jsou takzvané „hash tabulky“. Název je
odvozen z hash principu, který zajišťuje, že ukládání a testování
pozic bude velmi rychlé a teoreticky nezávislé na velikosti tabulek.
Pro odborníky naznačím princip: hash kód pozice, vzniklý jejím "semletím" je přímo adresou v tabulkách. Zobrazení pozice-hash není vzájemně jednoznačné, hash čísel je samozřejmě podstatně méně, než počet možných pozic. Algoritmus by měl být takový, že pro dostatečně "šachově" blízké pozice vzniká zaručeně jiné hash číslo. Teoreticky se to nemusí povést a mluvíme pak o hash kolizi. V historii počítačového šachu je několik těžko pochopitelných okamžiků, kdy silný program zahrál velmi slabý tah a situaci nelze reprodukovat. Má se za to, že příčinou mohla být právě náhodná hash kolize.
V praxi ovšem rychlost stejně klesá s velikostí hash tabulek, protože do
hry vstupují dvě úrovně vyrovnávací paměti (odborně cache) počítače, které jsou
až 3x rychlejší než RAM. Pro určitou velikost hash tabulek už cache prostě
nestačí a celý proces se skokem citelně zpomalí.
Názorně to lze předvést v programu Fritz 7, jehož FritzMark je spojen se zavedeným
motorem a reaguje na změny nastavené hash velikosti.
Dostanete třeba toto (Core2Duo 6320, 1G RAM)
32M 1380 kN/s
256M 1334 kN/s
512M 1274 kN/s
789M 1257 kN/s
Pozor! Pro vyšší verze Fritze je už FritzMark samostatný program, který má svou hash a na změnu hash zavedeného motoru nijak nereaguje.
A protože cache u jednotlivých procesorů se liší velikostí, stupni,
strategiemi plnění, je výše popsaný jev těžko nějak exaktně postižitelný.
S hash tabulkami je spojen jednoduchý, ale zásadní problém. Velikost hash tabulek se dá nastavit a uživatelé vyžadují návod, jaká velikost je optimální.
Takový návod ovšem neexistuje, protože kdyby ano, počítač by si tabulky
jednoduše nastavil sám. Jak plyne z výše uvedeného, pro 95 procent pozic (a
možná ještě více) bez transpozic jsou klasické hash tabulky k ničemu a v
principu zdržují propočet.
Ale ve zbylých případech představují takovou akceleraci, že prostě
nemohou být ignorovány.
Optimální velikost pak závisí na tom, jaké pozice budeme analyzovat a jak jsme
viděli, dokonce i na procesoru a velikosti jeho vyrovnávacích pamětí.
Situaci zjednodušuje skutečnost, že hash tabulky dnes už neplní jen klasickou
funkci. Programátoři si řekli, že když už je máme, využijeme je i jinak.
Například jako prostředek pro aplikaci samoučení programu a také ke zkvalitnění
interaktivní analýzy s počítačem (permanentní hash tabulky).
Stále více expertů se kloní k jednoduchému doporučení „čím větší, tím líp“.
Takže pokud to hardware, Windows a motor dovolí, nastavte klidně i několik
gigabajtů.
Deep Fritz 10 benchmarky na Tom's hw
z roku 2008, chybí nejnovější procesory.
http://www.tomshardware.com/2008/02/08/intel_skulltrail_part_3/page14.html
Benchmark je sice od staršího Fritze 9, ale obsahuje i procesory i7.
http://www.jens-hartmann.at/Fritzmarks/
Sedat, obsahuje nové procesory
http://www.sedatcanbaz.com/chess/?page_id=28
Cyclone /Toga
http://www.xtremesystems.org/forums/showthread.php?202139-Sandy-Bridge-Bulldozer-Computer-Chess-Test!
Je mnoho rychlostních testů procesorů, tzv benchmarků.
Pro odhad výkonu šachových programů je samozřejmě nejvěrohodnější test, který je
založen na šachovém propočtu.
Dlouholetou klasikou je FritzMark, ale ten bohužel neumí detekovat víc než 8
jader, což v poslední době vadí.
Zajímavou náhradou je motor Fire. Následuje návod k použití.
There are a lot of CPU benchmarks.
But for estimation of chess programs' performance we need benchmarks
based on chess computing.
FritzMark is a long years classic, but unfortunately it doesn't recognize more
then 8 threads. Last time it is a serious problem.
The interesting new benchmark tool is the Fire engine.
How to use it?
1. Run Fire
Free download
http://www.chesslogik.com/index.htm
On 64bit systems run the 64bit Fire.
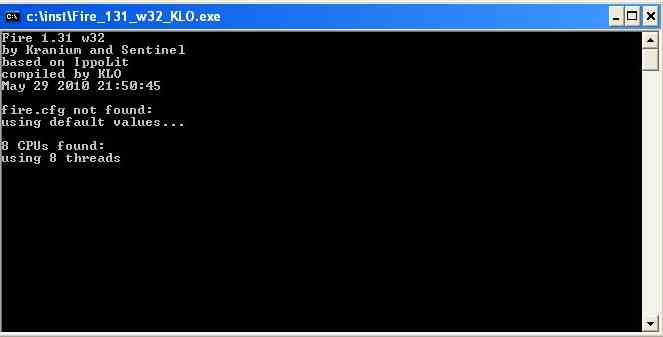
You can immediately see the number of threads include hyperthreading ones.
2. Enter the command
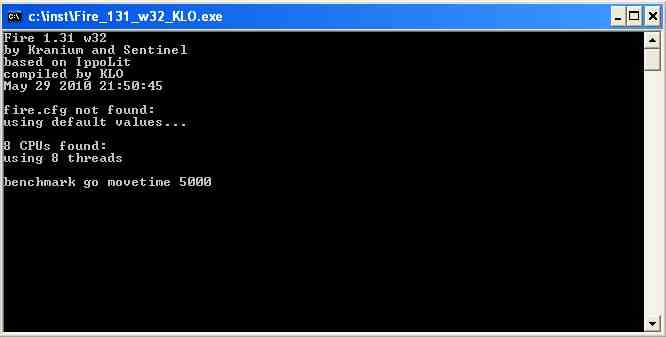
The number is running time, here 50 second
is entered.
Press ENTER.
3. The result
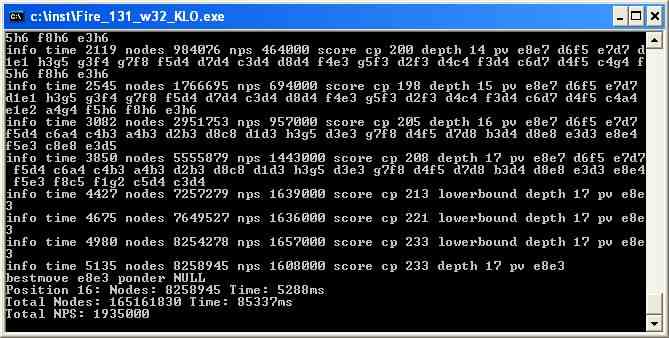
After the given time the benchmark 1935 kN/s is indicated.
http://www.liquidnitrogenoverclocking.com/vortex_f6.shtml
9000 USD je docela předražené
aktuální stav k 02.2013
1. Platforma
SUPERMICRO Tower 4U 2x LGA2011, iC602, 16x DDR3 ECC R, 8x
HS SATA (3,5"), Audio, IEEE1394a, 1280W,(80Plus Platinum)
Intel® Xeon® processor E5-2600 family; QPI up to 8GT/s
Up to 512GB DDR3 1600MHz ECC Registered DIMM; 16x DIMM sockets
8x Hot-swap 3.5" SATA HDD Bays
2x Exhaust Fans and 4x Internal Fans
1280W Redundant High-efficiency Digital Power Supplies w/ PMBus
80 PLUS, Platinum Level (95%)


Cena platformy kolem 43 000 bez DPH
2. Procesory
INTEL Xeon (8-core) E5-2650 2,0GHZ/20MB/LGA2011
cca 25 000 bez DPH za jeden kus
3. ECC Reg paměti
Cena za 8G modul 1450 Kč bez DPH slušných 64G teda přijde na cca
11 500 Kč bez DPH.
Celkově vyjde 16 jádro něco přes 100.000 Kč.
Martin Thoresen používá v projektu nTCEC (new Thoresen Chess Engines Competition) tento hardware.
CPUs: 2 x 8 core Intel Xeon E5-2689 @ 3300 MHz CPU
Coolers: 2 x Corsair H80i
Motherboard: Asus Z9PE-D8 WS
RAM: 32 GB Samsung MV-3V4G3D/US @ 8-8-8-24
PSU: Corsair AX 760
SSDs: 2 x Samsung 840 Pro 128 GB @ Raid 0
Case: Silverstone Raven RV03B-WA
Obrázek najdete zde http://www.tcec-chess.net/viewtopic.php?f=13&t=20 (až na konci stránky).